
티스토리 뷰
목표 : 네이버쇼핑에서 내가 원하는 키워드에 대한 도출 결과 추출
- 항목 : 상품명, 링크, 가격, 등록일, 카테고리, 리뷰, 별점
1. 페이지 살펴보기 (개발자 도구)
2. Beautifulsoup 를 통한 상품 목록 추출
-> 실패 : 5개 상품까지만 가져옴.
3. Selenium, Beautifulsoup 조합을 통한 상품 목록 추출
-> 실패 : 40개 상품 가져오지만, 이미지 일부를 로딩하지 못함
4. Json 파일 요청을 통한 목록 추출
-> 성공 : 드디어 모든 상품 정보를 가져옴
1. 페이지 살펴보기 (개발자 도구)


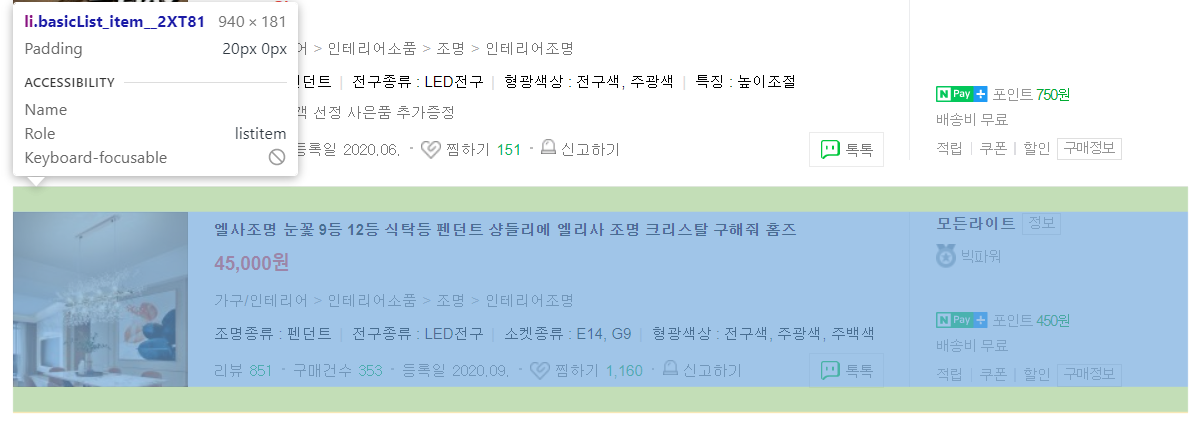

개발자 도구를 통해서 각각의 상품 정보를 li 태그(class:basicList_item__2XT81)나 div 태그(class:basicList_inner__eY_mq)를 통해서 접근이 가능하며, 각각의 상품에서 div 태그의 이미지/상품/업체 정보에 매핑되는 class 를 지정하면 데이터에 접근이 가능할 것이라는 방향성으로 추출을 진행하고자 하였다.
2. Beautifulsoup 를 통한 상품 목록 추출
1) URL : 검색어 (=엘사 12등)
https://search.shopping.naver.com/search/all?query=%EC%97%98%EC%82%AC+12%EB%93%B1&cat_id=&frm=NVSHATC2) BeautifulSoup 를 활용하여, li 태그 접근
soup = BeautifulSoup(res.text, "lxml")
items = soup.find_all("li", attrs={"class":"basicList_item__2XT81"})우선 여기까지 확인하여 가져오는 items 의 갯수를 확인 결과.............."5개"가 나옵니다.
분명 홈페이지에서는 40개의 리스트가 보였었는데, 혹시나해서 다시 개발자모드에서 확인 결과 스크롤을 내릴때마다 추가로 10개씩 리스트가 더 보이는 것을 발견할 수 있었습니다.
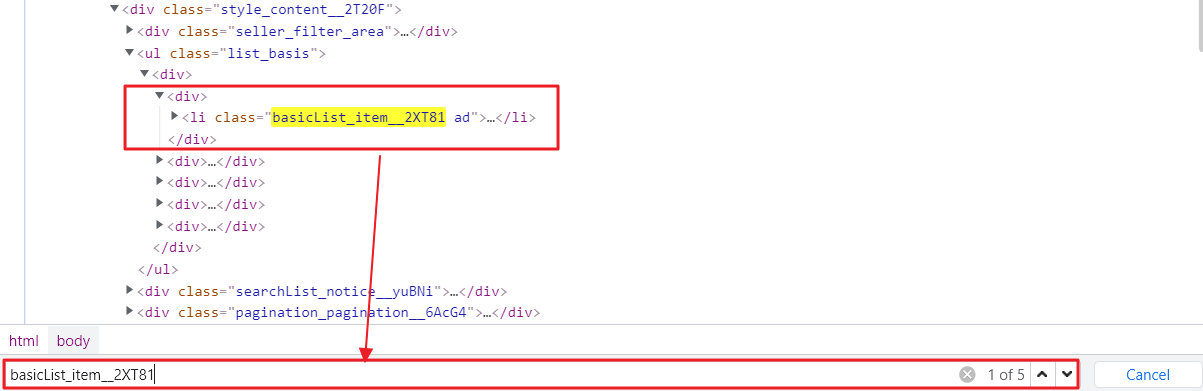

뭔가 이상한 걸 느꼈지만, beautifulsoup 을 위해서는 맨 아래까지 스크롤을 내릴 수 있는 요청을 할 수 없었기 때문에 다음단계 selenium 을 이용하여 페이지를 맨 아래로 내릴 수 있는 방법을 활용하기로 했습니다.
사실, 또 하나의 selenium 을 하기로 결정한 부분은 썸네일을 표현하는 a > img 이미지 태그가 개발자 도구에서는 보였으나, 실제 앞에서 추출한 items에서는 보이지 않았었습니다.

for idx, item in enumerate(items):
infos = item.find("div", attrs={"class":"basicList_img_area__a3NRA"})
print(infos)
3. Selenium, Beautifulsoup 조합을 통한 상품 목록 추출
1) selenium 을 활용하여 chrome webdriver 정보 로드 => navershopping 사이트 접속
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
url = "https://search.shopping.naver.com/search/all?query=%EC%97%98%EC%82%AC+12%EB%93%B1&cat_id=&frm=NVSHATC"
browser.get(url)2) 접속 페이지에서 스크롤을 가장 아래로 내리는 작업 진행
pre_scrollHeight = browser.execute_script("return document.body.scrollHeight") #이전 페이지 높이
interval = 2 #sleep time
while True:
#스크롤을 가장 아래로 내림
browser.execute_script("window.scrollTo(0, document.body.scrollHeight)")
time.sleep(interval) #페이지 로딩 대기
curr_scrollHeight = browser.execute_script("return document.body.scrollHeight") #현재 높이
#현재 높이 과거 높이 비교
if pre_scrollHeight == curr_scrollHeight:
break
pre_scrollHeight = curr_scrollHeight이 부분에서는 일부 javascript 를 활용한다.
chrome webdriver에서 제공하는 execute_script 메소드를 활용하여 javascript 코드 실행
> 1단계 : 현재 페이지 높이를 추출하여 pre_scrollHeight 값에 저장한다.
pre_scrollHeight = "document.body.scrollHeight" 결과
> 2단계 : 페이지 맨 아래로 스크로 이동 실행
window.scrollTo(0, document.body.scrollHeight)
> 3단계 : 스크롤 내리는 짧은 delay 고려
time.sleep(interval)
> 4단계 : 현재 페이지 높이를 추출하여 curr_scrollHeight에 저장한다.
curr_scrollHeight = "document.body.scrollHeight" 결과
> 5단계 : curr_scrollHeight 값과 pre_scrollHeight 값과 비교하여 같은 경우 종료

하지만 이렇게 했을때 역시, li 단위의 상품은 46개를 검색하지만, 세부 이미지 정보는 가져오지 못하는 문제가 발생했다. 실제 해보면 알겠지만, 5개 미만으로 가져온다.
(본 포스팅에서는 여기까지 설명을 하고, 스크롤 내리는 크기를 줄여가며 이미지를 불러오면 된다는 팁을 공유드림)
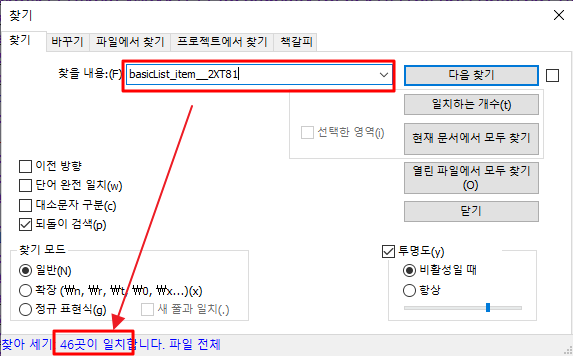
마지막 상품에 대한 정보를 추출하는 부분은 다음과 같이 처리할 수 있다.
soup = BeautifulSoup(browser.page_source, "lxml")
items = soup.find_all("li", attrs={"class":"basicList_item__2XT81"})
for idx, item in enumerate(items):
img = item.find("a", attrs={"class":"thumbnail_thumb__3Agq6"}).find("img")["src"]
title = item.find("a", attrs={"class":"basicList_link__1MaTN"})["title"]
category = item.find("div", attrs={"class": "basicList_depth__2QIie"}).get_text()
price = item.find("span", attrs={"class": "price_num__2WUXn"}).get_text()
print("-"*80)
print("[{} 번째 상품]".format(idx+1))
print("title : {}".format(title))
print("img : {}".format(img))
print("category : {}".format(category))
print("price : {}".format(price))
browser.quit()selenium을 통해서 브라우저의 최하단으로 간 시점에서 browser의 현 시점의 page_source 를 가져올 수 있다.
그 이후로는 일반적인 beautifulsoup 에서 파싱하며 각각의 데이터를 추출할 수 있다.

본 포스팅 작성 시점은 21년 12월 3일임에 따라 이를 따라 실행하시면 다른 결과가 나올 수 있음.
결과적으로 selenium + beautifulsoup 조합을 통해서 네이버 쇼핑의 상품목록을 가져올 수 있었다.
하지만, 실제 파싱을 해보면서 느끼겠지만, get_text 영역의 데이터를 가져오는데 자잘한 귀찮은 일들이 발생한다.
예를 들면, 등록일/리뷰/구매건수 등 마지막 라인에 있는 정보는 모두 span 태그에 동일한 class 명(="basicList_etc__2uAYO")을 가지고 있다. 그럼 이를 파싱하기 위해 find_next_sibling() 등을 호출해야 하는 ....
여튼 깔끔한 표현과 더욱 효율적인 처리를 위해 다음 포스팅에서 json 파일을 활용한 네이버 쇼핑 상품 검색 결과를 보여줄 수 있도록 할 예정이다.
사실, 본 포스팅을 작성하기 전까지 이미지가 나오지 않는 부분을 해결하지 못했다가 포스팅을 작성하면서 코드를 다시 보다가 방법을 알게되었다.(역시 글로 적으면서 설명하려고 하니 스스로도 많은 공부가 되는 듯 싶다.)
이 방법을 진행하다가 어려운 부분이나 막히는 부분이 있으면 언제든 댓글로 문의주시면 바로 답변드리겠습니다.^^
스스로 해 보라고 했던 부분에 대해서도 필요하면 방법 공유하겠습니다.!!
4. Json 파일 요청을 통한 목록 추출 (=> 다음 포스팅에서..)
'개발 > 파이썬(PYTHON)' 카테고리의 다른 글
| [PYTHON] 네이버 부동산 상가 매물 크롤링하기 (2) | 2022.03.02 |
|---|---|
| [PYTHON] 네이버 쇼핑 상품 목록 가져오기 (2/2) (7) | 2022.01.23 |
| Python 자료 구조 정리 (list, dictionary, tuple, set) (0) | 2021.10.29 |
| [Python] matplotlib.pyplot 활용한 그래프 동적 업데이트 (2/2) (0) | 2021.01.04 |
| [Python] matplotlib.pyplot 활용한 그래프 동적 업데이트 (1/2) (0) | 2021.01.03 |
- Total
- Today
- Yesterday
- Export
- beautifulsoup
- 크롤링
- 평형정보
- PYTHON
- DICTIONARY
- 대항력있는 임차인
- 경매
- 개발자도구
- 부동산
- 상가
- pandas
- 아파트
- 경제적 자유
- 네이버 부동산
- eum.go.kr
- 네이버 주식
- 네이버쇼핑
- 단지정보
- 크몽
- matplotlib
- tkinter
- 파이썬
- REST API
- 매물
- cortarNo
- json
- pyplot
- Excel
- 네이버
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 |